Problem and Constraints
Generic chat systems were hallucinating details and missing the right retrieval depth for dense philosophical and structured texts.
- I had to keep answers source-grounded while supporting both micro-detail and high-level conceptual questions.
- The retrieval path had to stay explainable so users could trace every answer back to evidence.
- I needed an architecture that could add graph workflows without destabilizing core QA performance.
My Approach
Considered: I evaluated a single-vector retrieval pipeline for all question types.
Chose: I chose hierarchical retrieval with intent routing so detail, structural, and conceptual prompts get the right evidence shape.
Rejected: I rejected one-size retrieval because it produced weak grounding for precise verse-style lookups and noisy context for broad synthesis.
Considered: I considered generating answers first and attaching citations afterward.
Chose: I chose evidence assembly before generation to force source-first reasoning.
Rejected: I rejected post-hoc citation attachment because it increases hallucination risk and weakens traceability.
Considered: I considered open graph extraction from free-form model output.
Chose: I chose ontology-constrained GraphRAG extraction with evidence links and refinement loops.
Rejected: I rejected unconstrained extraction because it creates brittle relations that are hard to validate against source text.
System Design
Loading diagram…
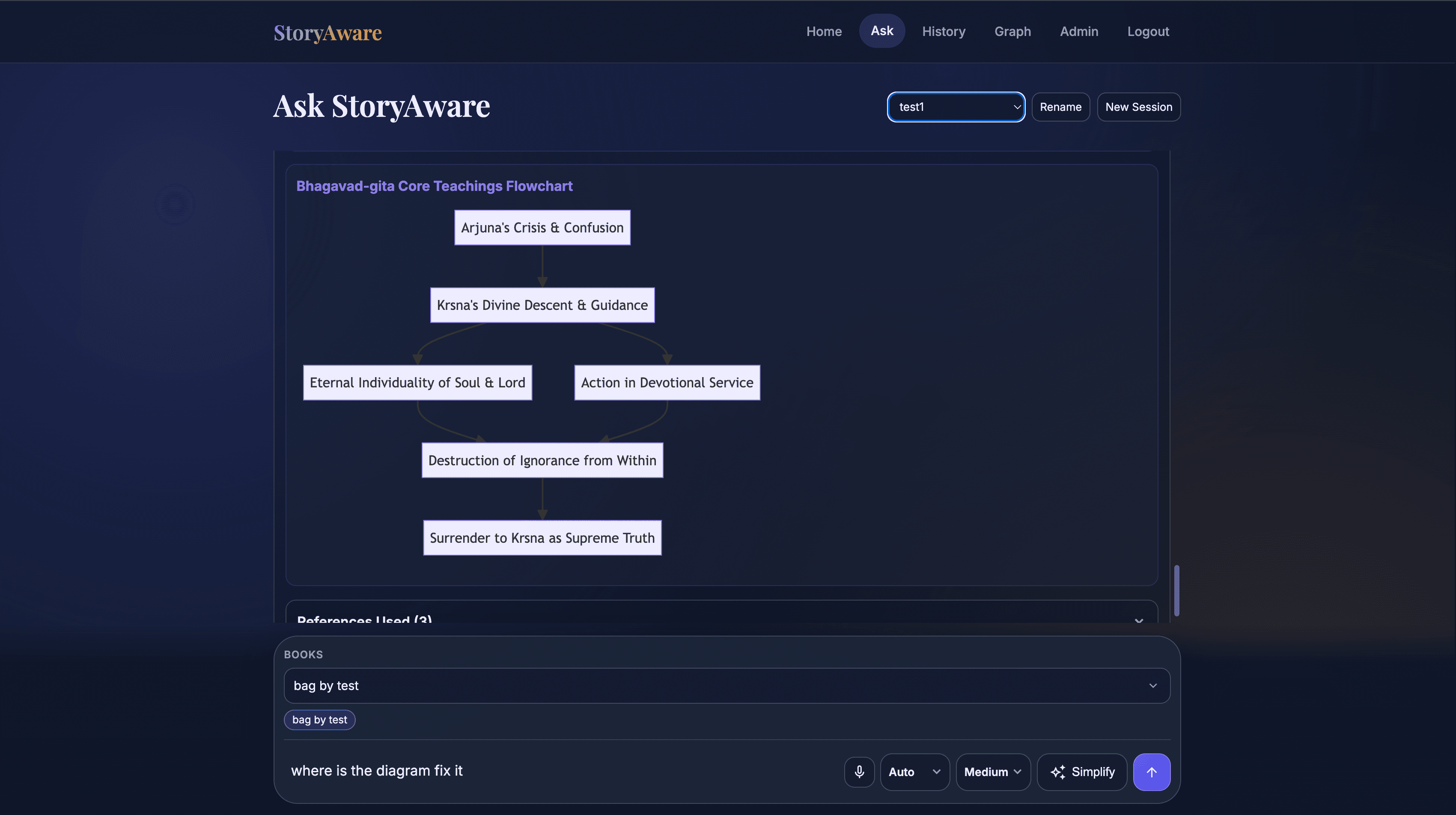
Each question is routed by intent, matched to chunk/chapter/book retrieval depth, and assembled into evidence before generation. Graph context can be injected only after evidence selection, so outputs stay grounded while still supporting concept-level reasoning.
This project runs on my self-hosted stack - HAProxy, DNS, TLS, and PostgreSQL. See how I run projects →
Implementation Highlights
- Hierarchical retrieval flow that combines chunk-, chapter-, and book-level evidence.
- Question-type routing for detail, structural, conceptual, and mixed queries.
- Graph-aware extraction path constrained by ontology and evidence links.
- Admin-governed access model with curated corpus and session-aware conversations.
Tech Stack
Outcomes
- Answers are grounded with source-first context and reduced hallucination risk.
- Retrieval quality improves by matching abstraction level to question type.
- Architecture supports extending into graph workflows without losing traceability.
Retrospective
Problem: A single-vector-index approach could not reliably serve both micro-fact and big-picture questions.
What I tried: I introduced multi-level retrieval and question routing before generation so evidence shape matches user intent.
What I'd do differently: I would add a dedicated automated evaluation harness earlier to quantify grounding quality continuously.